데이터 분석 학습일지🐣
6일차 - 통계 기초 예습+복습(온라인 강의)
boiled egg
2023. 6. 28. 08:55
Date : 2023-06-27
Topic : 기초 통계량, 회귀 분석, 상관계수
Note
통계학의 기본 개념
- 확률과 통계 - 모집단, 표본, 신뢰 구간
- 기하와 벡터 - 공간벡터, 평면
→고등 수학을 바탕으로 정규성 검정, 분산 분석 등 통계량 분석 & 선형대수학을 바탕으로한 주성분분석(PCA)
- TO-DO
- 확률과 통계 개념을 정리
- 통계적 방법론을 활용하여 분석 기법 사용(목표!)
대표값과 기초 통계량
- 대표값 : 자료 특성을 나타낼 수 있는 대표성을 띠는 수치
- 기초 통계량
- 중심경향성 : 데이터 분포의 중심을 보여주는 값
- 퍼짐 정도 : 자료가 얼마나 흩어져 있고 얼마나 모여있는지
- 왜도 : 분포의 좌우 비대칭성 정도
- 첨도 : 분포의 뾰족한 정도
etc
중심 경향성 (Central Tendency)
: 말 그대로 중심으로 모이는 경향.
- 중심 경향성을 나타내는 통계량
- 최빈값(Mode) : 가장 빈번하게 나타나는 값, 범주형 자료에서 대표값으로 최빈값을 주로 사용.
- 중앙값(Median) : 자료를 크기 순으로 나열했을 때 가운데 위치. 순서형 자료의 대표값으로 적합한 통계량. 이상치에 크게 영향 받지 않음.
- 평균값
- 산술 평균(Arithmetic Mean, Mean) : 자료 값을 모두 더해 자료 수로 나눈 값. 주로 연속형 자료에 사용. 이상치에 영향을 크게 받을 수 있음.
- 가중 평균(Weighted Mean) : 자료 중요도에 따라 가중치를 부여한 평균.
- 기하 평균(Geometric Mean) : 성장률 등 이전 시점에 대한 비율에 대한 평균을 구할 때 유용.
ex) CAGR(평균 성장률), 주가 상승률
회귀 분석⭐
: 변수 사이의 모형을 구한 뒤 적합도를 측정해내는 분석 방법. (대표적 : 선형 회귀 모형)
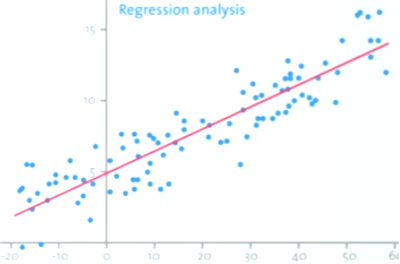
- 종속변수 : 결과
- 독립변수 : 종속변수를 설명하기 위한 변수
- 회귀 분석을 공부하는 이유 : 보통 결과를 설명하기 위해 하나의 변수만 영향을 주지 않음.
- 회귀 분석의 장점
- 대부분 결과를 설명하는 요인이 매우 많음
- 둘 이상 변수 간의 관계를 보여주는 통계적 방법
- 종속변수에 영향을 미치는 독립변수의 영향력 판단 가능
- 회귀 분석의 주의점
- 인과관계를 설명해주지는 못함
공분산, 상관행렬
*part 1 : ch 3-4 강의 참고(보면서 실습)
[데이터 분석] - [공분산 분석] or [상관 분석] - 상관 관계 확인


→ 공분산 분석은 각 변수의 범위가 달라서(ex: age 0.42~80(범위 79.58), fare 0~512.32(범위 512.32))
상관 관계의 비교가 어려울 수 있다. 이때는 상관 분석을 쓰면 좀 더 균일한 수치를 볼 수 있다.
→ 어떤 변수가 주요한 요인인지, 영향을 미쳤는지 파악할 수 있다.
상관계수
- 피어슨 상관계수(Pearson Correlation Coefficient)
- -1~1 사이 값을 가짐
- 절대값이 0.5~0.7 이상이면 강한 상관관계 (상황에 따라 기준이 조금 다름)
- -0.2~0.2 정도인 경우 약한 상관관계거나 없다고 해석
엑셀 데이터 탐색 실습
- Kaggle
- 데이터 분석 경진대회 플랫폼
- 기업 또는 단체에서 빅데이터 제공
- 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁
- 캐글에서 제공하는 데이터와 문제를 바탕으로 의견 공유
- 기업은 이를 바탕으로 정보와 인사이트 get
- 유저는 다양한 데이터 및 분석 경험
- 데이터 실습을 위한 엑셀 예제 CSV 파일 찾기(Kaggle)
- 필요한 데이터 검색
- data dictionary, data explorer, summary 확인
- [Download All]
- csv 파일을 엑셀로 연결
데이터 분석 도구를 사용해서 데이터 분포 파악하기
타이타닉호 탑승자 RAW데이터 - 요금(Fare) 데이터 분류 및 데이터 분석 - [기초 통계량]
내림 열 =FLOOR.MATH(A2)
내림2 열 =FLOOR.MATH(A2/2)*2
내림5 열 =FLOOR.MATH(A5/5)*5



엑셀로 히스토그램 그리기
- 필요한 데이터를 수집
- 구하고자 하는 결과
- [피벗 테이블] - [범위 설정] - 필요한 값 필드 선택
ex) 타이타닉호 생존자 중 성별 or Pclass에 따른 생존률 - 목적에 맞게 행/열/값 설정
ex) 생존률이므로 값(value) 필드를 평균으로 변경 - 필요에 따라 시각화 → 피벗 차트
이상치 탐지
*온라인 강의 참고
사분위수(IQR) 활용 이상치 탐지
Q1 제1사분위수 7.9104
Q3 제3사분위수 31
IQR Q3-Q1 23.0596