데이터 분석 학습일지🐣
27일차(2) - SQL 기초 문법 (GROUP BY, ORDER BY, ALIAS)
boiled egg
2023. 7. 27. 15:18
Date : 2023-07-26
Topic : GROUP BY, ORDER BY, ALIAS
Note
데이터 분석의 목적
쌓여 있는 날 것의 데이터를 의미를 갖는 '정보'로 변환. 이때 의미 있는 정보는 통계치로 나타낼 수 있다. (아래 더 구체적으로 작성)
그리고 정보들을 범주(category)별로 묶어줄 수 있는데 이때 사용하는 것이 GROUP BY이다.
GROUP BY
: 동일한 범주끼리 묶어서 통계를 내준다.
- ex ) 성씨별 회원수를 Group by로 쉽게 구해보기
SELECT name, COUNT(*)
FROM users u
GROUP BY name ;
- 위 쿼리가 실행되는 순서 : from → group by → select
1. from users : users 테이블 데이터 전체를 가져온다.
2. group by name : users 테이블 데이터에서 같은 name을 갖는 데이터를 합친다.
3. select name, count(*) : name에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 센다.
예) 이, 이, 김, 김, 박 이렇게 데이터가 있었다면, 이는 2개, 김은 2개, 박은 1개!
GROUP BY의 기능 : 통계
- 최대(max)
- 최소(min)
- 평균(avg)
- 합계(sum)
- 개수(count)
select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;⭐최솟값, 평균, 합계를 구하고 싶을 땐 위 구문에서 최댓값을 min, avg, sum으로 치환해주면 된다!
예외로 개수(count)를 구할 땐
select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명
group by 범주별로 세어주고 싶은 필드명;이 규칙으로 하면 된다.
ORDER BY
: 문자열(ㄱ-ㅎ or A-Z), 시간(숫자 0-9) 기준 데이터를 깔끔하게 정렬하는 기능.
아래와 같이 정렬하고자 하는 필드를 넣어 작성해주면 된다.
select name, count(*) from users
group by name
order by count(*);기본적으로 오름차순(asceding)으로 정렬되며(default값이라 아무 것도 안 써도 됨) 내림차순(descending)으로 하고 싶을 땐 DESC를 뒤에 적어준다.
내림차순은 시간, 날짜 등 최근 기록을 확인할 때 편리하다.
- ex) like를 많이 받은 순서대로 '오늘의 다짐'을 출력해보자
select * from checkins
order by likes desc;
- 위 쿼리가 실행되는 순서 : from → group by → select → order by
1. from users: users 테이블 데이터 전체를 가져온다.
2. group by name : users 테이블 데이터에서 같은 name을 갖는 데이터를 합친다.
3. select name, count( ) : name에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 센다.
예) 이, 이, 김, 김, 박 이렇게 데이터가 있었다면, 이는 2개, 김은 2개, 박은 1개겠죠!
4. order by count(*) : 합쳐진 데이터의 개수에 따라 오름차순으로 정렬한다.
- ex ) 웹개발 종합반의 결제수단별 주문건수 세어보기
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method;👉 만약 order by가 추가된다면? order by는 맨 나중에 실행된다. (결과물을 정렬해주는 것이기 때문!)
- 위 쿼리가 실행되는 순서 : from → where → group by → select
1. from orders: users 테이블 데이터 전체를 가져온다.
2. where course-title = "웹개발 종합반" : 웹개발 종합반 데이터만 남긴다.
3. group by payment-method : 같은 payment-method을 갖는 데이터를 합친다.
4. select payment-method, count(*) : payment-method에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 센다.
예) CARD, CARD, kakaopay 이렇게 데이터가 있었다면, CARD는 2개, kakaopay는 1개!
Alias
: 쿼리가 길고 복잡해지면 헷갈리기 쉬우므로 Alias(별칭) 기능을 활용한다.
혼동을 최소화하고 원하는 이름으로 결과를 출력할 수 있다.
- 테이블명 뒤에 붙이기 (이하 orders -> o로 표기 가능)
select * from orders o
where o.course_title = '앱개발 종합반'- 출력될 필드에 붙이기 (count(*) 필드가 cnt로 출력됨)
select payment_method, count(*) as cnt from orders o
where o.course_title = '앱개발 종합반'
group by payment_method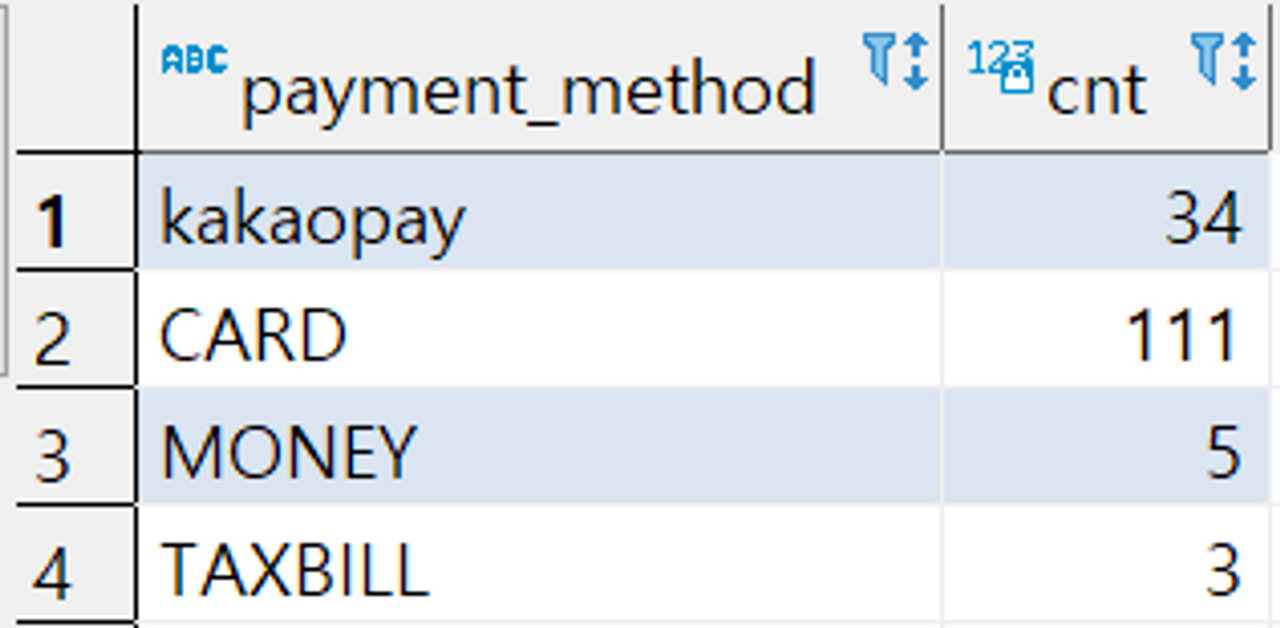
연습문제
1. Gmail 을 사용하는 성씨별 회원수 세어보기
SELECT name, COUNT(*)
FROM users u
WHERE email LIKE '%gmail.com'
GROUP BY name ;2. course_id별 '오늘의 다짐'에 달린 평균 like 개수 구해보기
SELECT course_id, AVG(likes)
FROM checkins c
GROUP BY course_id ;3. 네이버 이메일을 사용하여 앱개발 종합반을 신청한 주문의 결제수단별 주문건수 세어보기
SELECT payment_method, COUNT(*)
FROM orders o
WHERE email LIKE '%naver.com'
AND course_title = '앱개발 종합반'
GROUP BY payment_method ;새로 배운 내용
- 에러가 안 나는 쿼리를 작성하기 위해서는 SQL 쿼리가 실행되는 순서를 아는 것이 중요
- 오름차순(asceding)/default, 내림차순(descending)/DESC
- 내림차순은 시간, 날짜 등 최근 데이터부터 확인할 때 편리.
회고
- [ max, min, avg, sum (@@값을 알고 싶은 필드명) ]
↔ count (세어보려는 필드명)
※구문이 살짝 다르다. 헷갈림 주의! - 예제2 문장 해석이 헷갈려서 계속 같은 실수를 한다.
[course_id별 '오늘의 다짐'에 달린 평균 like 개수 구한다]라고 했을 때 '개수'라는 단어 때문에 계속 count를 쓰는데, '평균'이 포인트이므로 avg(likes)로 써야 한다. → 반복해서 다시 풀어보기 - 자주 하는 실수 :
- select * ← 전체값을 수정하지 않는다.
- 결과 : 구하고자 하는 필드와 통계치가 나오지 않는다.
- 해결안 : *을 [필드명, 통계]으로 정확히 작성한다.
- select문 안에 count(*)만 적는다.
- 결과 : 원하는 통계치는 나왔지만 각각 어떤 범주에 대한 통계치인지는 나오지 않는다.
- 해결안 : select문 안에 group by에 들어간 필드를 똑같이 적어준다.
→ [select 필드명, 통계값 from 테이블명]
- select * ← 전체값을 수정하지 않는다.
원하는 결과가 출력되지 않을 땐, SQL 쿼리의 실행순서에 따라 차근차근 생각해봐야 어디서 쿼리를 잘못 짰는지 가장 빠르고 정확하게 찾아낼 수 있다.