Topic : 설득력 있는 의사결정을 위한 데이터 시각화 Tool, Tableau (태블로 기본 개념, 기본 차트 그리기)
Note
1. 데이터의 중요성 불확실한 사회에서 확실한 것이 있다! 이것은 ,바로, 비즈니스 과정에서 중요한 의사 결정들을 데이터 기반으로 하는 것이다. 데이터의 3V → 데이터 활용 고객 맞춤 추천 서비스 (1) Data Literacy (데이터를 보고 활용할 수 있는 능력) : 데이터를 보는 것이 아니라 탐색을 통해 자신이 이해하고, 이를 다른 사람과 대화와 협업을 통해 찾은 통찰을 공유하는 능력
(2) ‘데이터 시각화’ : 데이터에 색상과 모양 그리고 사람들의 시선을 끌 수 있는 요소를 배치해 데이터를 시각적으로 표현한 것 (3) ‘데이터 시각적 분석’ : 데이터 시각화를 통해 스토리텔링 및 인사이트를 찾는 분석 기법 (4) DT : 디지털 트랜스포메이션, 기업 당면 과제, 산재되어 있는 데이터를 집중화시키고, 비즈니스에 적극적으로 활용할 수 있도록 하고 데이터에 대한 내부 문화 바뀌도록 유도 (5) DL : 데이터 리터러시, 기업 구성원의 당면 과제, DT로 마련한 데이터를 개인들이 언제나 접근해 비즈니스인사이트를 빠르게 발굴하는 능력 (6) DV : 데이터 비주얼리제이션, 데이터 리터러시를 강화하는 방법, 데이터를 시각적으로 표현하고 찾은 인사이트를 조직 내 공유 및 협업하는 과정
2. 태블로 (1) 태블로 : 데이터를 분석 및 시각화하는 BI(Business Intelligence) 솔루션, 비즈니스 운영 중 얻은 데이터를 수집, 저장, 분석하여 성과를 최적화하는 프로세스와 방법을 망라하는 포괄적인 용어
(2) 태블로 기본 컨셉 차원 vs 측정값
차원 : 그 숫자들로 만들어진 차트를 어떻게 나눠서 볼 것인지를 경정
측정값 : 숫자 형식, 액션(drag-drop 또는 double-click)을 통해 설정된 집계에 따라 하나의 차트 생성
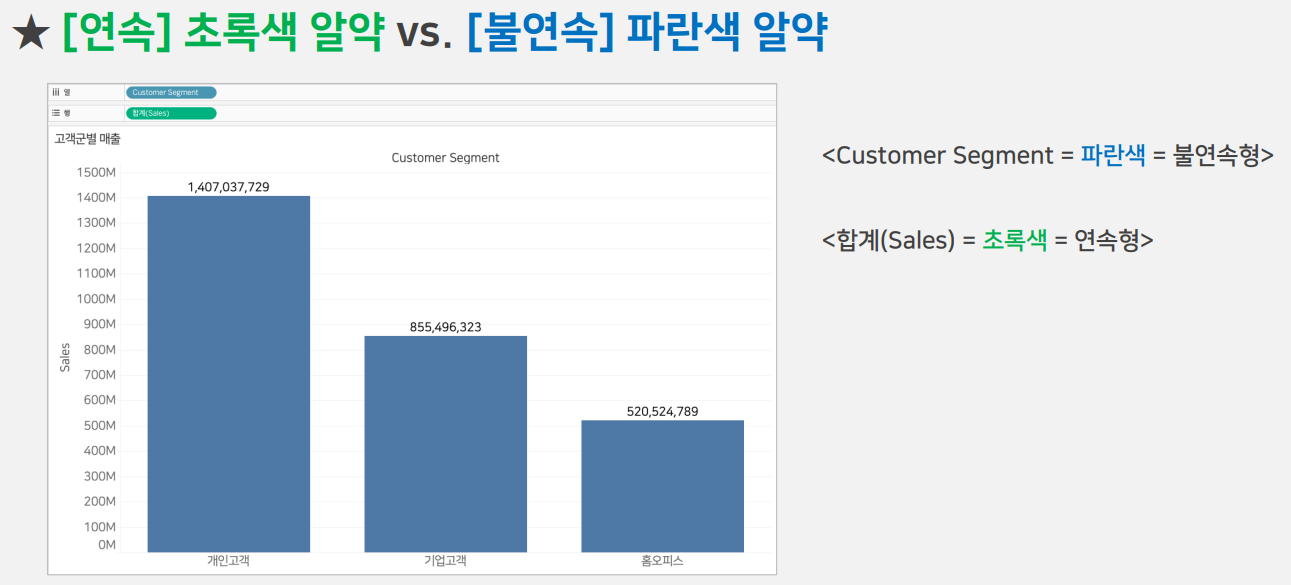
파랑색 박스 : 차원, 노랑색 박스 : 측정값(그 중 # 표시의 값은 숫자값을 나타냄)
(3) 불연속형(파란색) vs 연속형(초록색) ⭐
불연속형 : 연속적이지 않고 각각 끊어져서 다루는 것
연속형 : 처음부터 끝까지 이어지는 것
(4) 태블로 차트 부분 전체 분석 : 전체에서 각각의 요소들이 어느정도의 비중을 차지하고 있는지 확인에 적합
누적 막대 차트
: 막대를 누적해서 만드는 차트
막대차트
: 만들기 용이, 항목별로 나눠서 보는데 적합, 카테고리, 순위, 추세를 보는데 유용 : 태블로에서는 측정값에 있는 데이터 원본 필드 중 초록색 연속형 필드(위도, 경도는 제외)를 더블 클릭하면 기본적으로 막대 차트가 생성됨 : 기본적으로 집계 방식을 통해 우선 차트를 만들고 이것을 분할해서 보는 기준은 차원의 값으로 결정되는데, 그 출발은 막대 차트부터 시작하게 됨 - 레이블에 넣은 자료를 정렬하려면 레이블을 클릭하고 정렬 등 원하는 커스터마이징을 하면 됨
라인 차트
: 시간 순서에 따른 추세 확인에 유용, 만들기 용이 - 만드는 법 날짜 유형 필드를 활용하여 간단하게 만듦
파이 차트
: 시간 순서에 따른 추세 확인에 유용, 만들기 용이
도넛 차트
: 파이 차트가 가지지 않는 요약적인 정보 표시 가능 시간 순서에 따른 추세 확인에 유용, 만들기 용
트리맵
: 살펴보아야 하는 요소가 많은 경우에는 파이차트나 도넛 차트 보다는 트리맵을 사용하는 것이 적합함
마침 이전 글에 데이터 시각화에 필요한 그래프 종류를 정리해놓은 것이 있어서 참고하면 좋을 것 같다.
# 2006-02-14 기준으로 최근 30일 동안 영화를 대여하지 않은 고객을 찾으세요. -- 다시 풀기
SELECT first_name, last_name
FROM customer cu
LEFT JOIN rental r ON r.customer_id = cu.customer_id AND
TIMESTAMPDIFF(DAY, r.rental_date, '2006-02-14')
<= 30
WHERE r.rental_date IS NULL;
/* 가장 최근에 대여한 영화 중, 가장 늦게 반납한 상위 10명의 고객 이름과 그들이 대여한 영화의 이름, 그리고 대여 기간을 출력해 주세요.
고객 이름은 customer_name, 영화 이름은 movie_title, 대여 기간은 rental_duration으로 출력해주세요. */
SELECT
CONCAT(first_name, ' ', last_name) AS customer_name, -- 고객 이름
f.title AS movie_title, -- 대여한 영화 이름
TIMESTAMPDIFF(DAY, r.rental_date, r.return_date) AS rental_duration -- 대여 기간
FROM rental r
JOIN customer cu ON cu.customer_id = r.customer_id
JOIN inventory i ON i.inventory_id = r.inventory_id
JOIN film f ON f.film_id = i.film_id
ORDER BY r.return_date DESC -- 1.가장 늦게 반납한
LIMIT 10; -- 2.상위 10명
/*
SELECT TIMESTAMPDIFF(DAY, '2023-08-11 23:59:59', '2023-08-12 00:00:01') AS difference;
SELECT DATEDIFF('2023-08-12 00:00:01', '2023-08-11 23:59:59') AS difference;
*/
/* 각 직원의 매출을 찾고, 각 직원의 매출이 회사 전체 매출 중 어느 정도 비율을 차지하는지 찾으세요.
결과는 직원 ID, 직원 이름, 각 직원의 매출, 회사 전체 매출에 대한 비율(%)로 보여주세요. */
SELECT
sf.staff_id,
sf.first_name,
sf.last_name,
SUM(p.amount) AS staff_revenue,
ROUND(SUM(p.amount)/(SELECT SUM(amount) FROM payment)*100, 2) AS pay_per
FROM payment p
JOIN staff sf ON sf.staff_id = p.staff_id
GROUP BY sf.staff_id;
/* 각 고객별로 어떤 카테고리를 가장 많이 대여하는지 알고 싶습니다. 각 고객별로 가장 많이 대여한 영화 카테고리와
해당 카테고리에서의 총 대여 횟수, 그리고 해당 고객 이름을 조회하는 SQL 쿼리를 작성해주세요.
자주 대여하는 카테고리에 동률이 있을 경우 모두 보여주세요. */ -- 다시 풀기
SELECT
CONCAT(cu.first_name, ' ', cu.last_name) AS customer_name, -- 고객 이름
c.name, -- 카테고리 이름
COUNT(*) AS cnt_category -- 해당 카테고리 대여 횟수 카운트
FROM category c
JOIN film_category fc ON fc.category_id = c.category_id
JOIN inventory i ON i.film_id = fc.film_id
JOIN rental r ON r.inventory_id = i.inventory_id
JOIN customer cu ON cu.customer_id = r.customer_id
GROUP BY cu.customer_id, c.name
HAVING cnt_category = (
SELECT COUNT(*) FROM rental r2
JOIN inventory i2 ON i2.inventory_id = r2.inventory_id
JOIN film_category fc2 ON fc2.film_id = i2.film_id
WHERE r2.customer_id = cu.customer_id
GROUP BY fc2.category_id
ORDER BY COUNT(*) DESC
LIMIT 1) --
ORDER BY cu.customer_id;
/* -- 다시 풀어보기!
SELECT
C.first_name, C.last_name,
CA.name,
COUNT(*) rental_count
FROM customer C
JOIN rental R ON R.customer_id = C.customer_id
JOIN inventory INV ON INV.inventory_id = R.inventory_id
JOIN film_category FC ON FC.film_id = INV.film_id
JOIN category CA ON CA.category_id = FC.category_id
GROUP BY C.customer_id, CA.name
HAVING COUNT(*) = (
SELECT MAX(rental_count)
FROM (
SELECT
R2.customer_id,
FC2.category_id,
COUNT(*) rental_count
FROM rental R2
JOIN inventory INV2 ON INV2.inventory_id = R2.inventory_id
JOIN film_category FC2 ON FC2.film_id = INV2.film_id
WHERE R2.customer_id = C.customer_id
GROUP BY R2.customer_id, FC2.category_id
) CUSTOMER_RENTAL_COUNT
)
*/
employees 테이블로 연습하기
# employees 테이블에서 'Geert', 'Parto' 등의 이름을 가진 사원의 emp_no 알아내기 (emp_no 와 이름 출력하기)
SELECT
emp_no,
CONCAT(first_name, ' ', last_name) AS name
FROM employees
WHERE first_name IN ('Geert', 'Parto') OR last_name IN ('Geert', 'Parto');
# departments 테이블에서 'Sales', 'Marketing' 부서의 dept_no 알아내기 (dept_no 와 부서명 출력하기)
SELECT dept_no FROM departments
WHERE dept_name IN ('Sales', 'Marketing');
# salaries 테이블에서 100000 이상의 연봉을 받는 사원의 emp_no와 연봉 출력하기
SELECT emp_no, salary FROM salaries
WHERE salary >= 100000;
# titles 테이블에서 'Senior Engineer', 'Staff'의 title을 가진 사원의 emp_no와 직위명 출력하기
SELECT emp_no, title FROM titles
WHERE title IN ('Senior Engineer', 'Staff');
# 사원번호(emp_no) 10005번인 사원의 이름과 성별 출력하기
SELECT first_name, last_name, gender FROM employees
WHERE emp_no = 10005;
# Marketing 부서에서 일하는 모든 사원의 emp_no와 부서명 출력하기
SELECT emp_no, dept_name FROM departments d
JOIN dept_emp de ON de.dept_no = d.dept_no
WHERE dept_name = 'Marketing';
# 'Senior Engineer' 직위에서 일하는 사원 중 연봉이 70000 이상인 사원의 emp_no, 직위명, 연봉 출력하기
SELECT
e.emp_no,
t.title,
MAX(s.salary) AS salary -- 2.사원번호를 기준으로 가장 높은 연봉을 출력한다(사원번호 중복 제외하기 위해)
FROM titles t
JOIN employees e ON e.emp_no = t.emp_no
JOIN salaries s ON s.emp_no = e.emp_no
WHERE title = 'Senior Engineer' AND salary >= 70000
GROUP BY e.emp_no; -- 1.연봉 협상으로 한 사람의 연봉이 매년 상승하기 때문에
# 사원의 성(last_name)이 'Markovitch'인 사원의 emp_no, 이름, 성 출력하기
SELECT emp_no, first_name, last_name FROM employees
WHERE last_name = 'Markovitch';
# 'Finance' 부서에서 'Senior Staff'로 일하는 모든 사원의 emp_no와 부서명, 직위명 출력하기
SELECT e.emp_no, dept_name, title
FROM employees e
JOIN dept_emp de ON de.emp_no = e.emp_no
JOIN departments d ON d.dept_no = de.dept_no
JOIN titles t ON t.emp_no = e.emp_no
WHERE title = 'Senior Staff' AND dept_name = 'Finance';
# 1990년에 고용된 모든 사원의 emp_no, 이름, 고용날짜 출력하기
SELECT
e.emp_no,
CONCAT(first_name, ' ', last_name) AS emp_name,
from_date
FROM employees e
JOIN salaries s ON e.emp_no = s.emp_no
WHERE from_date LIKE '%1990-%';
/* 현재 'Engineer' 직위를 가진 모든 사원의 emp_no와 직위명을 출력하기
(titles 테이블의 to_date는 직위의 종료일을 나타냅니다. '9999-01-01'은 아직 직위가 종료되지 않았음을 나타냅니다) */
SELECT emp_no, title FROM titles
WHERE title = 'Engineer' AND to_date LIKE '9999-%';
# 1995년에 고용된 사원 중 연봉이 60000 이상인 사원의 emp_no, 고용날짜, 연봉 출력하기
SELECT
e.emp_no,
e.hire_date,
s.salary
FROM employees e
JOIN salaries s ON s.emp_no = e.emp_no
WHERE s.salary >= 60000 AND e.hire_date LIKE '1995-%';
# 'Senior Engineer' 직위를 가지고 있는 사원들 중에서, 'd005' 부서에 속한 사원의 emp_no, 직위명, 부서번호 출력
SELECT de.emp_no, title, d.dept_no
FROM departments d
JOIN dept_emp de ON de.dept_no = d.dept_no
JOIN titles t ON t.emp_no = de.emp_no
WHERE title = 'Senior Engineer' AND d.dept_no = 'd005';
# 1990년부터 2000년까지 고용된 사원 중에서, 'Sales' 부서에서 일하고 있는 사원의 emp_no, 이름, 고용날짜, 부서명 출력
SELECT
e.emp_no,
CONCAT(first_name, ' ', last_name) AS emp_name,
e.hire_date,
dept_name
FROM employees e
JOIN dept_emp de ON de.emp_no = e.emp_no
JOIN departments d ON d.dept_no = de.dept_no
WHERE
(YEAR(e.hire_date) BETWEEN 1990 AND 2000) AND -- 2.이렇게 타입을 명시해주고 (YEAR()) 숫자(연도)로 비교하는 것이 더 정확
# ('1990-01-01' <= e.hire_date <= '2000-01-01') -- 1.DATETIME과 문자열이 혼합되어 있을 때 단순히 크다 작다로 비교하기 보다
dept_name = 'Sales';
# 현재 'Marketing' 부서에서 일하면서 연봉이 80000 이상인 사원의 emp_no, 부서명, 연봉 출력하기
SELECT
de.emp_no,
d.dept_name,
s.salary
FROM departments d
JOIN dept_emp de ON de.dept_no = d.dept_no
JOIN salaries s ON s.emp_no = de.emp_no
WHERE
dept_name = 'Marketing' AND
salary >= 80000 AND
de.to_date = '9999-01-01'; -- 문제에 '현재' 일하고 있다는 조건 있음. 놓치지 않도록 주의⭐
# 모든 부서에서 연봉 상위 5명의 사원의 emp_no, 부서명, 연봉 출력하기 -- 다시 풀기
SELECT s.emp_no, dept_name, salary
FROM salaries s
JOIN dept_emp de ON de.emp_no = s.emp_no
JOIN departments d ON d.dept_no = de.dept_no
ORDER BY salary DESC
LIMIT 5;
/*
정답:
SELECT emp_no, dept_name, salary
FROM (
SELECT
e.emp_no,
d.dept_name,
s.salary,
DENSE_RANK() OVER (PARTITION BY d.dept_name ORDER BY s.salary DESC) AS rank_in_dept
FROM employees e
JOIN dept_emp de ON e.emp_no = de.emp_no
JOIN departments d ON de.dept_no = d.dept_no
JOIN salaries s ON e.emp_no = s.emp_no
) AS RankedSalaries
WHERE rank_in_dept <= 5
ORDER BY dept_name, salary DESC;
*/
# 각 부서별로 연봉 평균이 가장 높은 직위를 가진 사원의 emp_no, 부서명, 직위명, 평균 연봉 출력하기
/* SELECT
*
FROM salaries s
JOIN dept_emp de ON de.emp_no = s.emp_no
JOIN departments d ON d.dept_no = de.dept_no
JOIN titles t ON t.emp_no = de.emp_no
정답:
SELECT rd.emp_no, rd.dept_name, rd.avg_salary
FROM (SELECT
e.emp_no, d.dept_name, AVG(s.salary) AS avg_salary,
DENSE_RANK() OVER (PARTITION BY d.dept_name ORDER BY AVG(s.salary) DESC) AS ranking
FROM employees e
JOIN dept_emp de ON e.emp_no = de.emp_no
JOIN departments d ON de.dept_no = d.dept_no
JOIN titles t ON e.emp_no = t.emp_no
JOIN salaries s ON e.emp_no = s.emp_no
GROUP BY e.emp_no, d.dept_name, t.title
) rd
WHERE rd.ranking = 1 */
8월 둘째주부터 2주 조금 안되는 시간 동안 진행한 프로젝트로, 밀렸던 SQL 코딩테스트 연습을 이제서야 올리게 됐다. 프로젝트 기간에도 물론 SQL을 사용했지만 파이썬이나 엑셀 같은 툴을 같이 사용하다보니 잠시 연습 안했다고 그새 감이 좀 죽었다. 그러다보니 '-- 다시 풀어보기' ← 라는 주석을 많이 달게 되었는데 제출 기한 상 어쩔 수 없이 오답노트 개념으로 학습일지를 적게 되었지만,,, 다시 연습하면 그만이니까 ㅎㅎ 어느 정도 감을 익혀야 자신 있게 SQL코테에서 써먹을 수 있을까 아직도 깜깜하고 걱정되지만 프로젝트를 비롯하여 그동안 배운 것들이 피와 살이 된 것 같아 감사한 점이 많다. 왜 내 회고는 항상 이렇게 감상적이게 되는지🥲 프로젝트가 끝난지 D+2인데 쉴 새 없이 다시 무언가를 준비해야 하는 게 아쉽기도 하면서 설렌다😎 아무튼!! 다시 열심히 공부하고, 체크해놓은 부분 잊지 않고 복습할 것. 이상 일지 작성 끝.
이번 프로젝트는 'Olist'라는 브라질 이커머스 플랫폼에서 제공하는 오픈 데이터를 사용하여 진행했다. 2016-2018 기간 동안 10만여 건 정도 되는 데이터로, 실제 데이터를 개인 정보를 제외하고 드라마에 등장하는 이름으로 변경해서 제공하다보니(왕좌의 게임) 많은 사람들이 프로젝트나 분석 연습에 사용하는 것으로 보인다. 확실히 더미 데이터만 만지다 실무와 흡사한 데이터와 과정을 거쳐보니, 어떻게 감을 잡고 시작하며 어려운 부분에선 여러 방식을 시도해보는 둥 단기간에 여러 스킬이 향상된 것을 체감할 수 있었다. 첫 프로젝트에서는 파이썬 위주로만 사용하던 방식을 이번엔 엑셀, 파이썬, SQL 이외 flourish나 다양한 협업툴을 접목시켜보았고 실제 현업과 가장 비슷한 느낌으로 진행했다.
가이드라인을 최대한 참고하며 따라 갔지만 짧은 기간 내 최대한의 성과를 내고 싶은 마음에 1, 2차 분석은 많이 헤매기도 하고 마땅한 결과가 나오지 않아 포기하고 싶은 마음도 있었다. 특히 목표 의식과 일정 관리 부분에서 반성할 점이 많았다. 일정 관리는 단기 프로젝트라는 점에서 마음이 조급해 일단 시작해버린 탓에 목표 의식이 흐려져 오히려 중간 중간 시간이 허비되는 일이 많았다. 첫 단추를 잘 꿰야 하는데 목적 없이 진행하면서 내가 이 데이터 분석을 '왜' 하는 것이며 어떤 것을 위해 '무엇을' 분석해야 하는지에 대한 의문이 들었다. 처음엔 그저 주어진 일을 시행하는 느낌으로 하다보니 진행을 하면 할수록 분명한 결과가 나오지 않았고 당연히 결과물은 엉망이었다. 중간 피드백을 받았을 땐 '넓은 주제, 얕은 분석'에 대한 지적이 있었고 방향성을 설정하는 것이 얼마나 중요한 일인지 그제서야 깨달았다. 당연히 갈피를 못잡으니 여러 방향에 대해 탐색하는 정도로만 분석을 했고 심층적인 결론을 낼 수 없었다.
따라서 전처리 및 도메인 정리는 마쳤으니 '누가 이 분석을 활용할 수 있을까?'란 생각으로 방향 설정을 했고 그제서야 프로젝트가 좀 더 수월해지기 시작했다. 주제에 대한 narrow down과 deep dive하여 발견한 결론을 어떻게 활용할 것인가에 대한 포인트를 앞으로도 잘 인지하고 있어야 겠다. 기간이 정해진 상태에 늦게 갈피를 잡다보니 분석에 대해 원하는 만큼 심층적인 결론과 임팩트 있는 인사이트는 도출하지 못했지만 개인적으로 더 시도하며 개선해보고 싶다.
# 2005년 8월에 각 스태프 멤버가 올린 매출을 스태프 멤버는 Staff Member 항목으로, 매출은 Total Amount 항목으로 출력
SELECT
s.staff_id AS 'Staff Member',
SUM(amount) AS 'Total Amount' -- 스태프 이름 쓰기
FROM payment p
JOIN staff s ON s.staff_id = p.staff_id
WHERE payment_date LIKE '%2005-08%'
GROUP BY s.staff_id;
# 각 카테고리의 평균 영화 러닝타임이 전체 평균 러닝타임보다 큰 카테고리들과 카테고리명과 해당 카테고리의 평균 러닝타임을 출력
SELECT c.name, AVG(length)
FROM film f
JOIN film_category fc ON fc.film_id = f.film_id
JOIN category c ON c.category_id = fc.category_id
GROUP BY c.name
HAVING AVG(length) > -- 각 카테고리의 평균 영화 러닝타임
(SELECT AVG(length) FROM film); -- 전체 평균 러닝타임
# 각 카테고리별 평균 영화 대여 시간을 출력하세요
SELECT
c.name,
AVG(TIMESTAMPDIFF(HOUR, r.rental_date, r.return_date)) AS rent_duration -- ⭐평균 영화 대여 시간
FROM rental r
JOIN inventory i ON i.inventory_id = r.inventory_id
JOIN film f ON f.film_id = i.film_id
JOIN film_category fc ON fc.film_id = f.film_id
JOIN category c ON c.category_id = fc.category_id
GROUP BY c.name;
/* DATE TYPE FORMAT
TIMESTAMPDIFF(unit, datatime_expr1, datetime_expr2)
unit: YEAR, MONTH, DAY, HOUR, MINUTE -- 모든 시간 타입을 사용할 수 있다!
*/
/* 새로운 임원이 부임했습니다. 총 매출액 상위 5개 장르의 매출액을 수시로 확인하고자 합니다.
Total Sales (각 장르별 총 매출액) 과 Genre (각 장르 이름) 으로 해당 데이터를 수시로 확인할 수 있는 view 를
top5_genres 로 만들고, 현재까지의 상위 5 장르의 매출액을 출력해주세요 */ -- 현업에서 많은 형태, (보고용) 태블로로 시각화도 많이 한다
CREATE VIEW top5_genres AS -- 뷰 생성
SELECT
c.name AS Genre,
SUM(p.amount) AS 'Total Sales'
FROM payment p
JOIN rental r ON p.rental_id = r.rental_id
JOIN inventory i ON i.inventory_id = r.inventory_id
JOIN film_category fc ON fc.film_id = i.film_id
JOIN category c ON c.category_id = fc.category_id
GROUP BY c.name
ORDER BY SUM(p.amount) DESC
LIMIT 5;
SELECT * FROM top5_genres; -- 생성된 뷰 출력
/* 뷰를 삭제할 땐
DROP VIEW top5_genres;
*/
# 2005년 5월에 가장 많이 대여된 영화를 찾으세요. 영화 제목과 대여 횟수를 보여주세요.
SELECT f.title, COUNT(*) AS cnt_rental
FROM rental r
JOIN inventory i ON i.inventory_id = r.inventory_id -- 오답 이유: 테이블 별칭 제대로 써주기
JOIN film f ON f.film_id = i.film_id -- ON절에 중복하거나 오타 주의
WHERE rental_date LIKE '2005-05%'
GROUP BY f.title
ORDER BY cnt_rental DESC
LIMIT 1;
# 대여된 적이 없는 영화를 찾으세요. -- outer join에 대한 이해 필요
SELECT f.title FROM film f
LEFT OUTER JOIN inventory i ON i.film_id = f.film_id -- 각 영화와 해당 영화의 재고 정보가 연결
LEFT OUTER JOIN rental r ON r.inventory_id = i.inventory_id -- 각 영화 복사본과 대여 기록이 연결
WHERE r.rental_id IS NULL; -- rental 테이블에 해당 영화 복사본에 대한 대여 기록이 없는 경우
# 평균 고객 지출보다 더 많이 지출한 고객을 찾으세요. 그들의 이름과 그들이 지출한 금액을 보여주세요. -- 다시 풀고 완벽히 이해! 특히 HAVING절
SELECT
CONCAT(c.first_name, ' ', c.last_name) AS customer_name,
SUM(p.amount) AS tot_spent
FROM customer c
JOIN payment p ON p.customer_id = c.customer_id
GROUP BY customer_name
HAVING tot_spent > ( -- 평균 고객 지출
SELECT AVG(sum_amount) -- 각 고객별 총지출의 평균 (112.531820)
FROM (
SELECT SUM(amount) as sum_amount
FROM payment
GROUP BY customer_id
) as sub_query -- 고객ID별 총지출을 하나의 테이블로 FROM절에서 사용
);
# 가장 많은 결제를 처리한 직원이 누구인지 찾으세요.
SELECT
CONCAT(s.first_name, ' ', s.last_name) AS staff_name,
COUNT(*) AS cnt_pay
FROM staff s
JOIN payment p ON s.staff_id = p.staff_id
GROUP BY s.staff_id -- 직원별로 그룹핑
ORDER BY cnt_pay DESC -- 직원별 결제 카운트를 내림차순 정렬
LIMIT 1;
# '액션' 카테고리에서 가장 높은 등급을 받은 상위 5개의 영화를 보여주세요.
SELECT title, rating -- NC-17이 가장 높은 등급
FROM film f
JOIN film_category fc ON fc.film_id = f.film_id
JOIN category c ON c.category_id = fc.category_id
WHERE c.name = 'Action'
ORDER BY rating DESC -- 도메인 지식
LIMIT 5;
# 각 영화 영상등급별의 영화 대여기간(film.rental_duration)의 평균을 찾으세요.
SELECT rating, ROUND(AVG(rental_duration), 2) AS avg_rent
FROM film
GROUP BY rating;
# 매장 ID별 총 매출을 보여주는 뷰를 생성하세요.
CREATE VIEW total_revenue AS
SELECT st.store_id, SUM(amount) AS tot_revenue
FROM staff s
JOIN payment p ON p.staff_id = s.staff_id
JOIN store st ON st.store_id = s.store_id
GROUP BY st.store_id;
SELECT * FROM total_revenue;
/* DROP VIEW total_revenue */
# 가장 많은 고객이 있는 상위 5개 국가를 보여주세요.
SELECT country, COUNT(*) AS cnt_customer
FROM country c
JOIN city ct ON ct.country_id = c.country_id
JOIN address a ON a.city_id = ct.city_id
JOIN customer cu ON cu.address_id = a.address_id
GROUP BY country -- 국가별로
ORDER BY cnt_customer DESC -- 고객수대로 정렬
LIMIT 5;
Topic : 배운 문법들을 활용하여 sakila 데이터로, 실전처럼 SQL 코딩테스트 문제 난이도별 풀어보기 (같은 문제도 여러 방법 사용해보기)
Note
SQL 코딩테스트 연습
기본 문제
/* category 테이블에서 "Comedy", "Sports", "Family" 카테고리의 category_id 알아내기
(category_id 와 카테고리명 출력하기) */ -- 실제 코테는 이런 조건 꼭 정확히 숙지하고 쿼리 작성!!
SELECT category_id, name FROM category
WHERE name IN ('Comedy', 'Sports', 'Family'); -- OR 연산자 사용 시, tab 활용(기니까)
# film_category 테이블에서 영화 아이디(film_id)가 2 인 영화의 카테고리 ID 알아내기
SELECT category_id FROM film_category
WHERE film_id=2;
# film_category 테이블에서 카테고리 ID별 영화 수 알아내기
SELECT category_id, COUNT(*) AS cnt_film
FROM film_category
GROUP BY category_id;
/* 카테고리가 Comedy 인 영화 수 알아내기
(category 테이블에는 카테고리 이름과 category_id, film_category 테이블에는 category_id와 각 영화 id가 있음) */
# JOIN 사용
SELECT COUNT(*) AS cnt_comedy
FROM category c
INNER JOIN film_category fc
ON c.category_id=fc.category_id
WHERE name='Comedy';
# 서브쿼리 사용
SELECT COUNT(*) FROM film_category
WHERE category_id = ( -- WHERE IN(또는 =) 구문으로 연관 있는 컬럼끼리 연결(중요)
SELECT category_id FROM category
WHERE name = 'Comedy'
);
/* Comedy, Sports, Family 각각의 카테고리별 영화 수 알아내기 (JOIN 사용하기)
(category 테이블에는 카테고리 이름과 category_id, film_category 테이블에는 category_id와 각 영화 id가 있음) */
SELECT c.name, COUNT(*) FROM film_category fc
JOIN category c ON c.category_id = fc.category_id
WHERE name IN ('Comedy', 'Sports', 'Family')
GROUP BY c.name
# 카테고리에 포함되는 각각의 영화 수가 70 이상인 카테고리 출력하기
SELECT c.name, COUNT(*) FROM category c
JOIN film_category fc ON fc.category_id = c.category_id
GROUP BY c.name
HAVING COUNT(*) >= 70
/* 각 카테고리에 포함된 영화들의 렌탈 횟수 구해보기
(각 카테고리별에 포함된 영화들의 총 렌탈 횟수와 각 카테고리명을 출력하는 것이 최종 목표)
- rental 테이블에 렌탈 기록이 있음
- inventory 테이블에 물품현황과 해당 물품(DVD)에 들어 있는 영화 아이디가 있음
- film_category 테이블에 영화 아이디에 매칭되는 카테고리 아이디가 있음
- category 테이블에 카테고리 아이디에 매칭되는 카테고리명이 있음 */
SELECT c.name, COUNT(*) -- 각 카테고리별 카운트 = 렌탈 횟수
FROM rental r
JOIN inventory i ON i.inventory_id = i.inventory_id
JOIN film_category fc ON fc.film_id = i.film_id
JOIN category c ON c.category_id = fc.category_id
GROUP BY c.category_id;
/* "Comedy", "Sports", "Family" 카테고리에 포함되는 영화들의 렌탈 횟수 출력하기 (카테고리명, 렌탈 횟수) */
SELECT c.name, COUNT(*) -- 각 카테고리별 카운트 = 렌탈 횟수
FROM rental r
JOIN inventory i ON i.inventory_id = i.inventory_id
JOIN film_category fc ON fc.film_id = i.film_id
JOIN category c ON c.category_id = fc.category_id
WHERE c.name IN ('Comedy', 'Sports', 'Family') -- 구하고자 하는 카테고리 조건 걸기
/*WHERE category.name = 'Comedy' OR
category.name = 'Sports' OR
category.name = 'Family' */
GROUP BY c.category_id;
# 카테고리가 Comedy 인 데이터의 렌탈 횟수 출력하기 (join으로 푸는게 더 효율적이지만 연습용으로 서브쿼리 사용)
SELECT COUNT(*) FROM rental r -- 렌탈 횟수 카운트
WHERE inventory_id IN -- 카테고리ID가 'Comedy'인 film_id를 인벤ID로 join해서
(SELECT inventory_id FROM inventory WHERE film_id IN -- 'Comedy' 카테고리 film_id가 인벤토리ID
(SELECT film_id FROM film_category WHERE category_id IN -- 카테고리ID가 'Comedy'인 film_id
(SELECT category_id FROM category WHERE name = 'Comedy') -- 카테고리ID가 'Comedy'
)
);
# 카테고리가 Comedy 인 데이터의 영화 갯수 출력하기 (JOIN 문법으로 작성해보세요)
SELECT COUNT(*) FROM category c
INNER JOIN film_category fc
ON c.category_id = fc.category_id
WHERE name = 'Comedy';
# 카테고리가 Comedy 인 데이터의 영화 갯수 출력하기 (서브쿼리 문법으로 작성해보세요)
SELECT COUNT(*) FROM film_category
WHERE category_id IN (
SELECT category_id FROM category
WHERE name = 'Comedy'
);
/* address 테이블에는 address_id 가 있지만, customer 테이블에는 없는 데이터의 갯수 출력 (RIGHT JOIN 사용)
OUTER JOIN 사용 시, 출력값에 맞게 기준이 테이블을 정하고 해당하는 조건을 설정할 때 주의(별칭이나 컬럼)*/
SELECT COUNT(*) FROM customer c
RIGHT JOIN address a
ON c.address_id = a.address_id
WHERE c.customer_id IS NULL; -- c테이블에 customer_id가 없는 조건
# `customer` 테이블에 대응되는 정보가 없는 `address` 테이블의 레코드 수를 세는 것
실전 문제 (난이도 up)
/* 캐나다 고객에게 이메일 마케팅 캠페인을 진행하고자 합니다.
캐나다 고객의 이름과, email 주소 리스트를 뽑아주세요 -- 딱 현업에서 이 느낌 */
SELECT first_name, last_name, email
FROM customer cu
INNER JOIN address ad ON cu.address_id = ad.address_id
INNER JOIN city ct ON ct.city_id = ad.city_id
INNER JOIN country ctr ON ctr.country_id = ct.country_id
WHERE country = "Canada" ;
# 젊은 가족 사이에서 매출이 저조해서, 모든 가족 영화를 홍보 대상으로 삼으려고 합니다. 가족 영화로 분류된 모든 영화 리스트를 뽑아주세요
SELECT title FROM film f
JOIN film_category fc ON fc.film_id = f.film_id
JOIN category ca ON ca.category_id = fc.category_id
WHERE ca.name = 'Family';
/* subquery + join
SELECT title
FROM film_category fc
JOIN film f ON fc.film_id = f.film_id
WHERE category_id = (
SELECT category_id FROM category c
WHERE name = 'Family'
); */
/* 가장 자주 대여하는 영화 리스트를 참고로 보고 싶습니다. 가장 자주 대여하는 영화 순으로 100개만 뽑아주세요
title (영화제목) 과 Rentals (렌탈 횟수) 로 보고 싶습니다. */
SELECT title, COUNT(*) AS Rentals
FROM rental r
INNER JOIN inventory i ON r.inventory_id = i.inventory_id
INNER JOIN film f ON f.film_id = i.film_id
GROUP BY title
ORDER BY Rentals DESC
LIMIT 100;
/* 각 스토어별로 매출을 확인하고 싶습니다. 관련 데이터를 출력해주세요
1) 스토어가 위치한 '도시, 국가' 를 Store 항목으로, 2) 스토어 ID 를 Store ID 로,
3) 각 스토어별 총 매출을 'Total Sales' 항목으로 출력해주세요 */ -- 다시 풀기
SELECT
CONCAT(CI.city, ', ', CO.country) AS 'Store',
ST.store_id AS 'Store ID',
SUM(PA.amount) AS 'Total Sales'
FROM payment PA
JOIN rental RE ON RE.rental_id = PA.rental_id
JOIN inventory INV ON INV.inventory_id = RE.inventory_id
JOIN store ST ON ST.store_id = INV.store_id
JOIN address AD ON AD.address_id = ST.address_id
JOIN city CI ON CI.city_id = AD.city_id
JOIN country CO ON CO.country_id = CI.country_id
GROUP BY ST.store_id;
/* 각 스토어의 스토어 ID, 도시, 및 국가를 알고싶습니다. 관련 데이터를 출력해주세요
store_id, city, country 로 보고 싶습니다. */
SELECT store_id, city, country
FROM store st
JOIN address a ON a.address_id = st.address_id
JOIN city ct ON ct.city_id = a.city_id
JOIN country c ON c.country_id = ct.country_id;
/* 가장 렌탈비용을 많이 지불한 상위 10명에게 선물을 배송하고자 합니다
가장 렌탈비용을 많이 지불한 상위 10명의 주소(address)와 이메일, 그리고 각 고객당 총 지불 비용을 출력해주세요 */
SELECT
CONCAT(cu.first_name, ' ', cu.last_name) AS customer_name,
a.address,
cu.email,
SUM(p.amount) AS tot_spent
FROM customer cu
JOIN payment p ON cu.customer_id = p.customer_id
JOIN rental r ON r.rental_id = p.rental_id
JOIN address a ON a.address_id = cu.address_id
GROUP BY cu.customer_id
ORDER BY tot_spent DESC
LIMIT 10;
/* 그룹화할 열이나 집계 함수를 정하지 않으면 데이터베이스가 그룹화할 방법을 알 수 없기 때문에 오류가 발생
따라서 GROUP BY절에서 'customer_name' 사용X, cu.customer_id라는 고객 아이디로 분류해주어야 한다. */
# actor 테이블의 배우 이름을 first name 과 last name 을 대문자로 Actor Name 항목으로 출력해주세요
SELECT UPPER(CONCAT(first_name, ' ', last_name)) AS "Actor Name"
FROM actor;
/* 언어가 영어인 영화 중, 영화 타이틀이 K 와 Q 로 시작하는 영화의 타이틀만 출력*/
# JOIN 사용
SELECT title FROM language l
JOIN film f ON f.language_id = l.language_id
WHERE
l.name = 'English' AND
f.title LIKE 'K%' OR f.title LIKE 'Q%';
# SUBSTRING 활용
SELECT title FROM language l
JOIN film f ON f.language_id = l.language_id
WHERE
l.name = 'English' AND
(SUBSTRING(f.title, 1, 1) = 'K' OR SUBSTRING(f.title, 1, 1) = 'Q'); -- K나 Q로 시작되는 제목
# SUBSTRING(string, start_position, length)
# 서브쿼리 사용
SELECT title FROM film
WHERE language_id IN
(SELECT language_id FROM language WHERE name = 'English')
AND
(title LIKE 'K%' OR title LIKE 'Q%');
/* Alone Trip 에 나오는 배우 이름을 모두 출력하세요
(배우 이름은 actor_name 항목으로 출력해주세요. 서브쿼리를 사용해보세요) */
# JOIN 사용
SELECT CONCAT(a.first_name, ' ', a.last_name) AS actor_name
FROM actor a
JOIN film_actor fa ON fa.actor_id = a.actor_id
JOIN film f ON f.film_id = fa.film_id
WHERE f.title = 'Alone Trip';
# 서브쿼리 사용
SELECT CONCAT(first_name, ' ', last_name) AS actor_name
FROM actor
WHERE actor_id IN
(SELECT actor_id FROM film_actor
WHERE film_id IN
(SELECT film_id FROM film
WHERE title = 'Alone Trip'))
8/8 수업 내용 문제를 2회독 해보니, 여러 형태 문제를 많이 풀어보는 것도 좋지만 복습하면서 같은 문제라도 반복적으로 풀어 보는 것이 개념 숙지 및 쿼리 작성 스킬 향상에 도움 되는 것이 눈에 띄게 체감된다. 특히 한 문제를 JOIN과 SUBQUERY를 모두 사용해보고 정답을 비교하며 쿼리 구조를 더 잘 이해할 수 있다. 확실히 각각 장단점이 있지만 여러 테이블을 참고해야 할 땐 조인을 사용하는 것이 훨씬 효율적이란 것을 자주 느꼈다. 그러다보니 무의식적으로 계속 조인만 사용하려고 하는데 배운 문법을 활용하면서 최대한 성능이 효율적이고 보기 좋은 쿼리를 작성할 수 있도록 많은 연습이 필요할 것 같다.